Programmable In-Network Aggregation for Communication-Aware Federated Learning in 5G RANs
Project Highlights
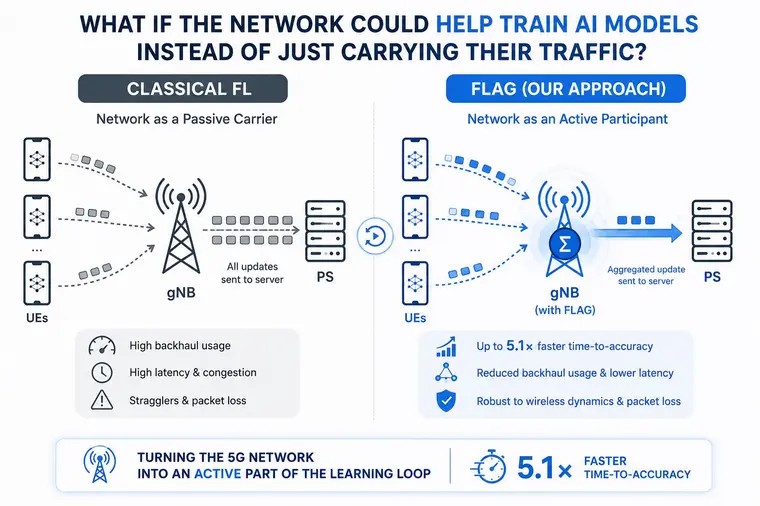
"What if the (computer) network could help train AI models instead of just carrying their traffic?"
Our idea was that communication and learning should not be treated as separate layers. By making the network an active participant in the training loop, we can accelerate distributed AI at the wireless edge.
Experts may have seen in-network aggregation before, but our FLAG 🏁 embeds line-rate model aggregation directly into the 5G gNB data plane. We also introduce loss-tolerant aggregation and deadline-aware scheduling mechanisms to preserve convergence while reducing communication bottlenecks.
This research was supported by the National Science Foundation (NSF) and the European Union with SMARTY.
Abstract
Federated Learning (FL) enables collaborative model training without sharing raw data, making it attractive for privacy-preserving applications at the wireless edge. However, when executed over real 5G networks, FL performance degrades due to uplink congestion, heterogeneous client capabilities, and intermittent connectivity. Most existing approaches attempt to mitigate these issues indirectly by optimizing clients (through adaptive participation, local training, or selection strategies) or by optimizing models (via pruning, quantization, or compression), but they ignore potential network bottlenecks.
This paper introduces FLAG, an FL architecture that embeds in-network aggregation directly into 5G gNodeBs, transforming the network into an active participant in the learning process. In particular, FLAG performs parameter aggregation at line rate within the 5G Service Data Adaptation Protocol layer and incorporates three mechanisms: Partial-Contribution Correction for loss-tolerant averaging, a timer-driven pipeline for real-time scheduling, and a deadline-based grouping strategy to mitigate stragglers.
Experiments with realistic wireless emulation show that FLAG achieves up to 5.1× faster time-to-accuracy and maintains accuracy within 0.8% of a loss-free baseline, while reducing gNB-to-server bandwidth by aggregating per-gNB rather than per-client. FLAG requires no modifications to clients or the parameter server, demonstrating how 5G-aware system design can make federated learning scalable, efficient, and resilient under real-world wireless conditions.
Index Terms—Federated Learning, Mobile Networks, Wireless, In-Network Aggregation, Grouping.
System Architecture